Appearance
使用卷积进行泛化
线性层中有大量可优化参数,能偶拟合(甚至过拟合)数据。但其在记忆训练集方面的表现优于对特性的泛化能力。由于需要全连接设置来检测图像中鸟或飞机的各种可能平移,我们即产生了过多的参数(使模型更容易记忆训练集),又缺乏位置不变性,我们可以通过数据增强来缓解这一问题。但这无法解决参数过多的问题。因此需要用卷积来替换神经网络单元中的密集全连接仿射变换。
卷积的意义
卷积可以实现局部性和平移不变性。在原来的处理中我们将图像是为一维视图并计算所有像素于一组权重相乘之后的加权和。而如果我们要识别物体通常需要关注邻近像素的排列方式,而对相距较远的像素组合则不感兴趣。要将这种直觉转为数学形式,可以计算一个像素与其最近像素的加权和
卷积的作用
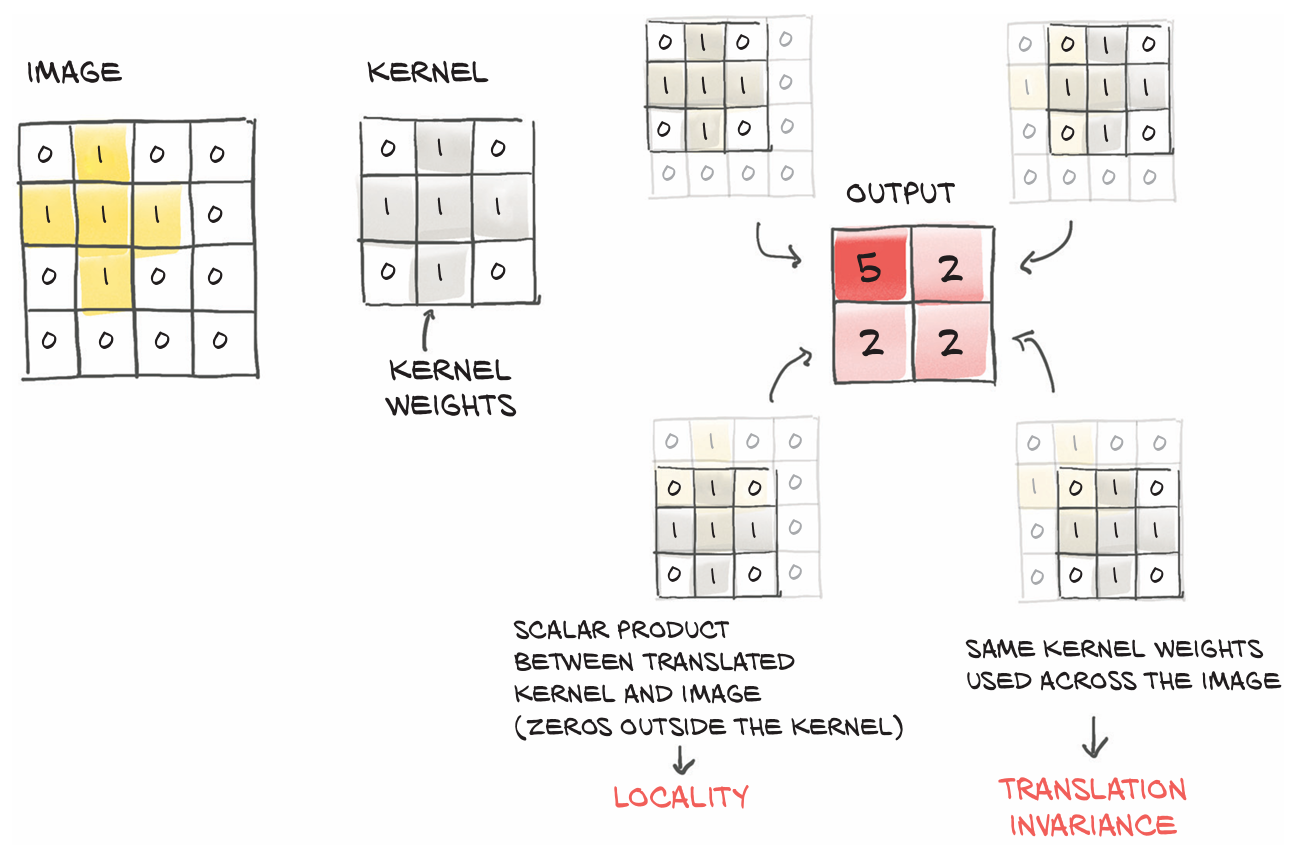 通过卷积操作有如下优势:
通过卷积操作有如下优势:
- 局部领域操作
- 平移不变性
- 参数更少的模型 即对于卷积层,参数数量不同于全连接模型那样取决于图像的像素数量而是取决于卷积核大小(如3×3、5×5等)以及再模型中决定使用的卷积滤波器(或输出通道)的数量。
卷积的实际应用
对于PyTorch中的卷积,nn.Conv1d用于时间序列,nn.Conv2d用于图像,nn.Conv3d用于处理立体数据或视频,在这里我们使用nn.Conv2d处理图像,同时我们需要指定输出特征的数量以及卷积核的大小。在这里我们每个像素有3个特征(RGB通道),输出通道可以任意设定;同时将卷积核大小固定为 kernel_size=3快速设定:
Python
conv = nn.Conv2d(3, 16, kernel_size=3)
print(conv.weight.shape, conv.bias.shape)Text
torch.Size([16, 3, 3, 3]) torch.Size([16])对于权重张量的形状推导: 由于卷积核的尺寸是 3×3×3(即in_ch×3×3)的三维卷积核。而一个卷积核只能提取一个输出通道,为了得到16个不同的特征图需要16个独立的三位卷积核,即:
也就是为什么conv.weight.shape的输出是torch.Size([16, 3, 3, 3])。由于我们由16个输出通道,因此需要16个偏置值,也即torch.Size([16])。 卷积可以让我们使用更小的模型寻找局部模式,其权重会在整个图像上进行优化,此外conv.weight与conv.bias都是随机初始化的,要通过卷积核调用图像需要将图像输入调整为
Python
img, _ = cifar2[0]
output = conv(img.unsqueeze(0))
print(img.unsqueeze(0).shape, output.shape)Text
torch.Size([1, 3, 32, 32]) torch.Size([1, 16, 30, 30])还可以输出图像与卷积后的图像,其中卷积后的图像丢失了一些像素。
边界填充
上面的问题是由于图像边界处理方式导致的副作用。若将卷积核作为 PyTorch会在输入图像内部滑动卷积,得到宽度为width - kernel_width + 1的水平位置和垂直位置,也即为什么每个维度会损失两个像素。 在PyTorch中也可以在图像边界进行填充,只需要为卷积增加参数padding = 1,增加的像素在计算时会被记作0。
Python
conv = nn.Conv2d(3, 16, kernel_size=3, padding=1)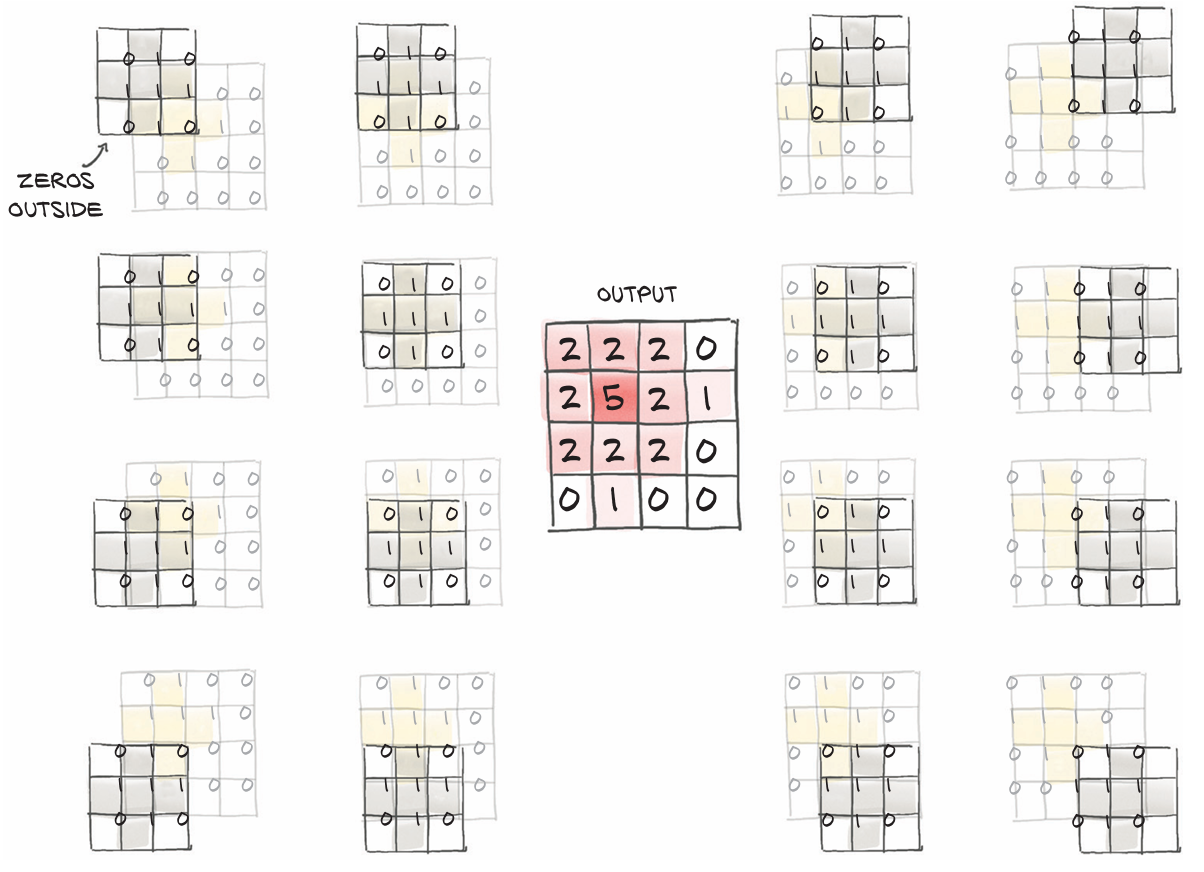 此时输入与输出张量是相同的。此外是否填充对权重和偏置的大小是不会影响的,这有助于我们将卷积与图像尺寸调整区分开;当我们处理更复杂的结构时若干卷积操作后张量的尺寸也会保持一致,以便进行加法或差分运算。
此时输入与输出张量是相同的。此外是否填充对权重和偏置的大小是不会影响的,这有助于我们将卷积与图像尺寸调整区分开;当我们处理更复杂的结构时若干卷积操作后张量的尺寸也会保持一致,以便进行加法或差分运算。
使用卷积检测特征
我们可以手动设置卷积权重来观察其对CIFAR图像的影响:
Python
with torch.no_grad():
conv.bias.zero_()
with torch.no_grad():
conv.weight.fill_(1.0 / 9.0)
output = conv(img.unsqueeze(0))
plt.imshow(output[0,0].detach(), cmap='gray')
plt.show()这会生成模糊版本的图像,输出的每个像素都是其输入相邻像素的平均值。还可以尝试不同的方法: