Appearance
深度学习的机制
学习就是参数估计
数据收集
依旧以最简单的线性回归为例,对于任意给定的数据我们可以定义其模型(前向传播)与损失函数(反向传播),并且通过给定变量与学习率,通过修改
Python
import torch
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0,-4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
def model(t_u, w, b): # 训练模型
return w * t_u + b
def loss_fn(t_p, t_c): # 损失函数
squared_diffs = (t_p- t_c)**2
return squared_diffs.mean()
w = torch.ones(())
b = torch.zeros(())
t_p = model(t_u, w, b) # 预测值
loss = loss_fn(t_p, t_c) # 损失值
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) -
loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
loss_rate_of_change_b =\
(loss_fn(model(t_u, b + delta, b), t_c) -
loss_fn(model(t_u, b - delta, b), t_c)) / (2.0 * delta)
learning_rate = 1e-2
w = w - learning_rate * loss_rate_of_change_w
b = b - learning_rate * loss_rate_of_change_b这里我们规定了一个最简单的一次函数:
梯度下降
当我们对
Python
def dloss_fn(t_p, t_c): # 对损失函数关于t_p求导
dsq_diffs = 2 * (t_p - t_c) / t_p.size(0)
return dsq_diffs
def dmodel_dw(t_u, w, b): # 对模型w求导
return t_u
def dmodel_db(t_u, w, b): # 对模型b求导
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.sum(), dloss_db.sum()])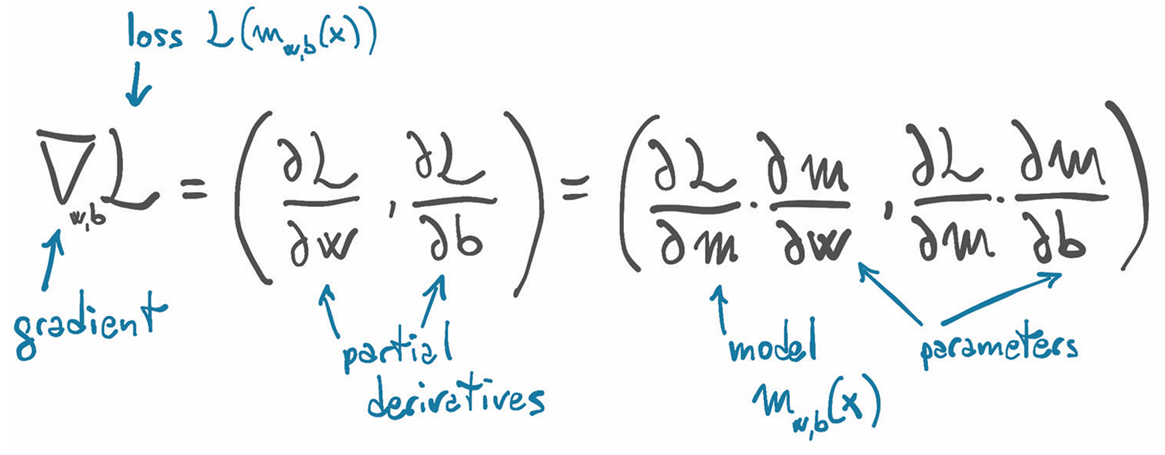 Tips:这里最开始写代码的时候使用自动补全写成了:
Tips:这里最开始写代码的时候使用自动补全写成了:dsq_diffs = (t_p - t_c)**2 / t_p.size(0)导数写错直接导致后续训练梯度爆炸模型误差越来越大,使用自动补全后需要注意检查
迭代拟合模型
周期(epoch)
将更新所有训练样本参数迭代的过程称为一个周期
Python
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # 前向传播
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b) # 反向传播
params = params - learning_rate * grad
print('Epoch %d, Loss: %f' % (epoch, float(loss)))
return params
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0,0.0]),
t_u = t_u,
t_c = t_c) # 初始化参数并训练Tips:这里最初写代码时遗漏了最初的参数b,即:params = w - learning_rate * grad(其实也是自动补全时未细看导致的),要注意训练时同时更新 w 和 b
注意到输出为:
Text
Epoch 1, Loss: 1763.884766
Epoch 2, Loss: 5802484.500000
Epoch 3, Loss: 19408029696.000000
Epoch 4, Loss: 64915905708032.000000
Epoch 5, Loss: 217130525461053440.000000
Epoch 6, Loss: 726257583152928129024.000000
Epoch 7, Loss: 2429183416467662896627712.000000
Epoch 8, Loss: 8125122549611731432050262016.000000
Epoch 9, Loss: 27176882120842590626938030653440.000000
Epoch 10, Loss: 90901105189019073810297959556841472.000000
Epoch 11, Loss: inf
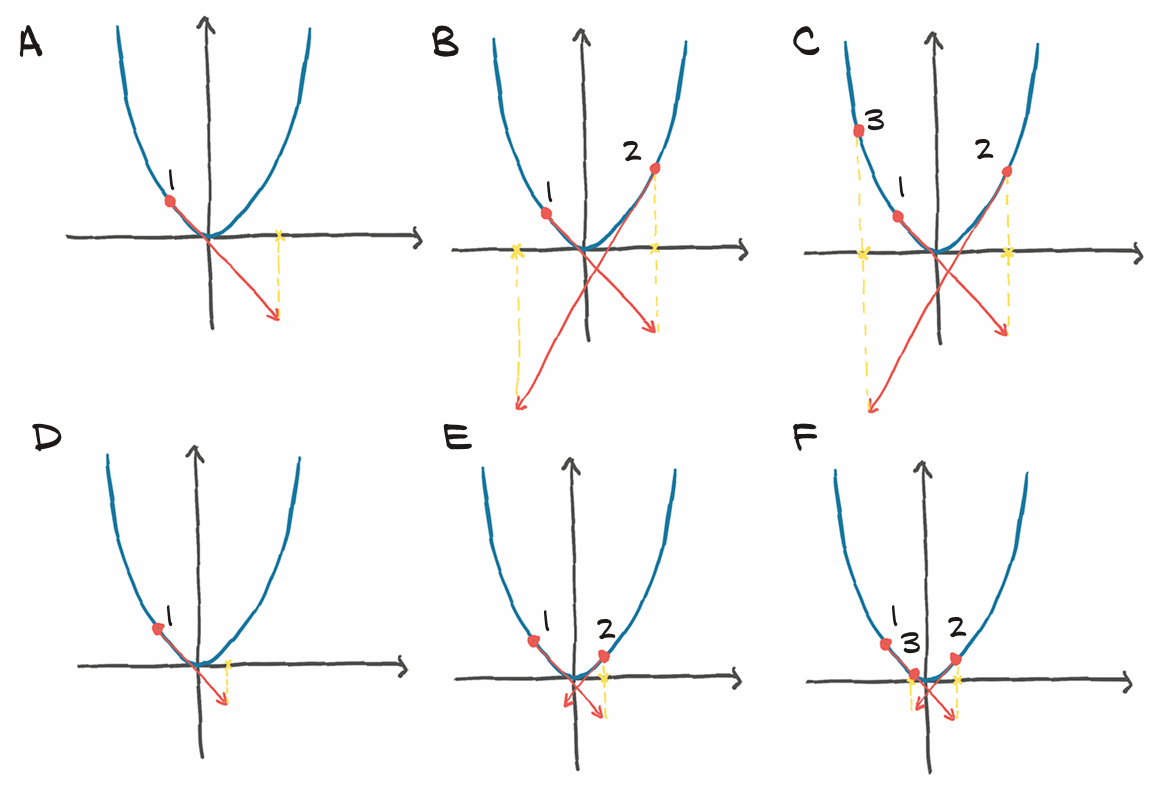
Epoch 12, Loss: inf这表明参数接收到的更新幅度过大导致数值震荡并发散,也即梯度选取太大导致的,参考下图。要限制学习率×梯度的大小只需要选择更小的学习率learning_rate = 1e-4
归一化输入
通过观察参数可以发现权重的梯度w是偏置b的50倍,因此权重可以显著影响学习率而偏置反而可能导致学习率的不稳定,可以通过调整输入值是梯度之间的差异不至于过大,我们将变量t_u进行归一化:t_un = 0.1 * t_u并修改训练参数为t_un
Python
t_un = 0.1 * t_u
training_loop(
n_epochs = 100,
learning_rate = 1e-2, # 这里同时将学习率增大了
params = torch.tensor([1.0,0.0]),
t_u = t_un,
t_c = t_c) # 初始化参数并训练而当我们增大训练周期n_epochs = 5000损失会进一步缩小也证明了梯度下降的优化方法是有效的。
可视化
最后将训练过程绘制为图表进行展示:
Python
params = training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0,0.0]),
t_u = t_un,
t_c = t_c) # 初始化参数并训练
from matplotlib import pyplot as plt
t_p = model(t_un, *params)
fig = plt.figure(dpi=600)
plt.xlabel("Temperature (°Fahrenheit)")
plt.ylabel("Temperature (°Celsius)")
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.show()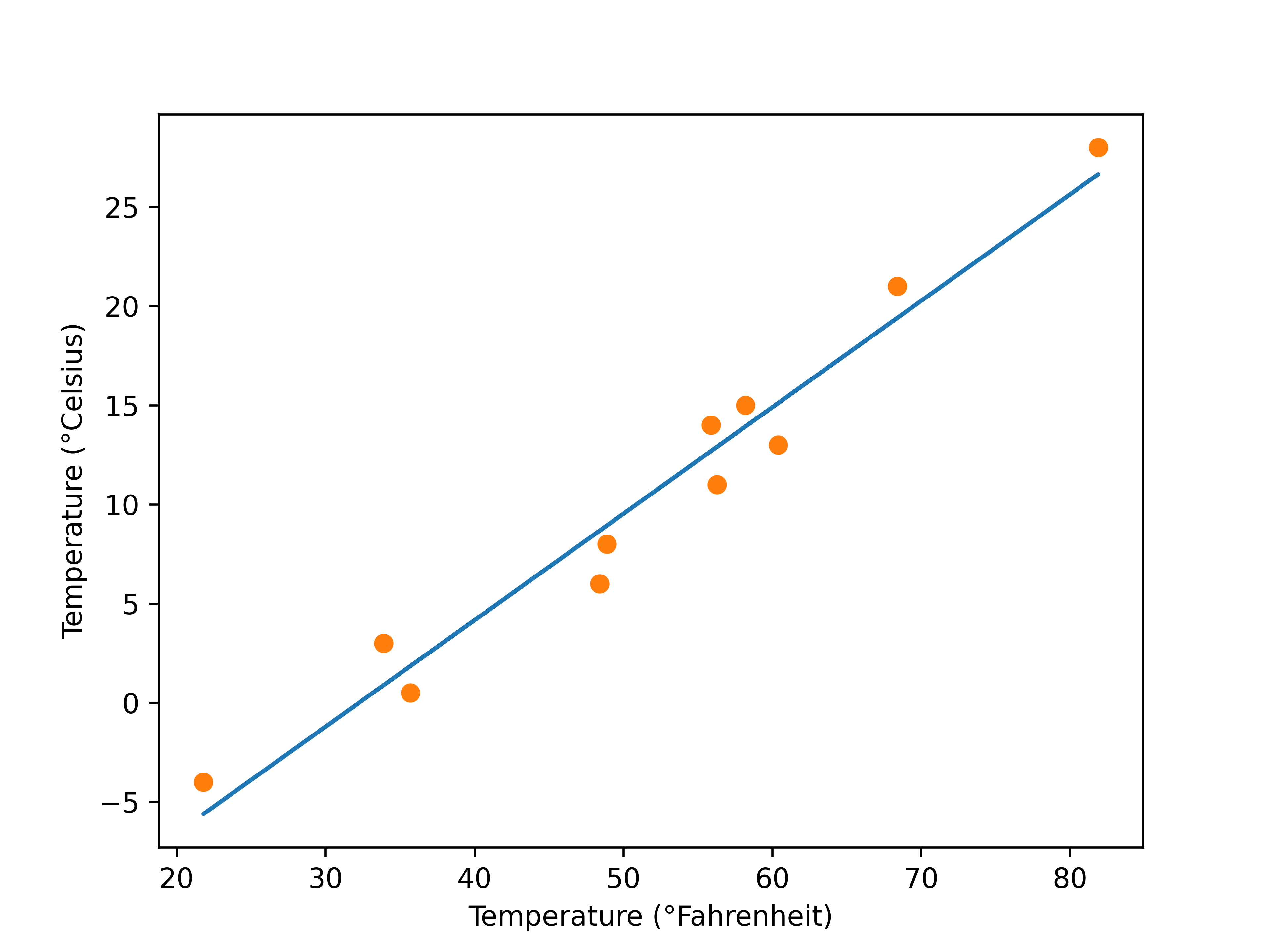
PyTorch自动求导
这部分在PyTorchBlitz学习笔记中已有介绍