Appearance
从图像中学习
微小图像数据集
下载CIFAR-10
图像识别数据集有很多,例如MNIST与CIFAR-10,此外datasets模块还提供了Fasion-MINST、SVHN、Coco和Omniglot等模块的便捷访问,我们使用torchvision模块下载CIFAR-10数据集:
Python
from torchvision import datasets
data_path = './data-unversioned/'
cifar10 = datasets.CIFAR10(root=data_path, train=True, download=True) # 实例化训练数据集
cifar10_val = datasets.CIFAR10(root=data_path, train=False, download=True) # 获取用于训练的数据集数据集class
我们可以通过__len__和__getitem__两个方法来对数据进行统一访问,如图所示: 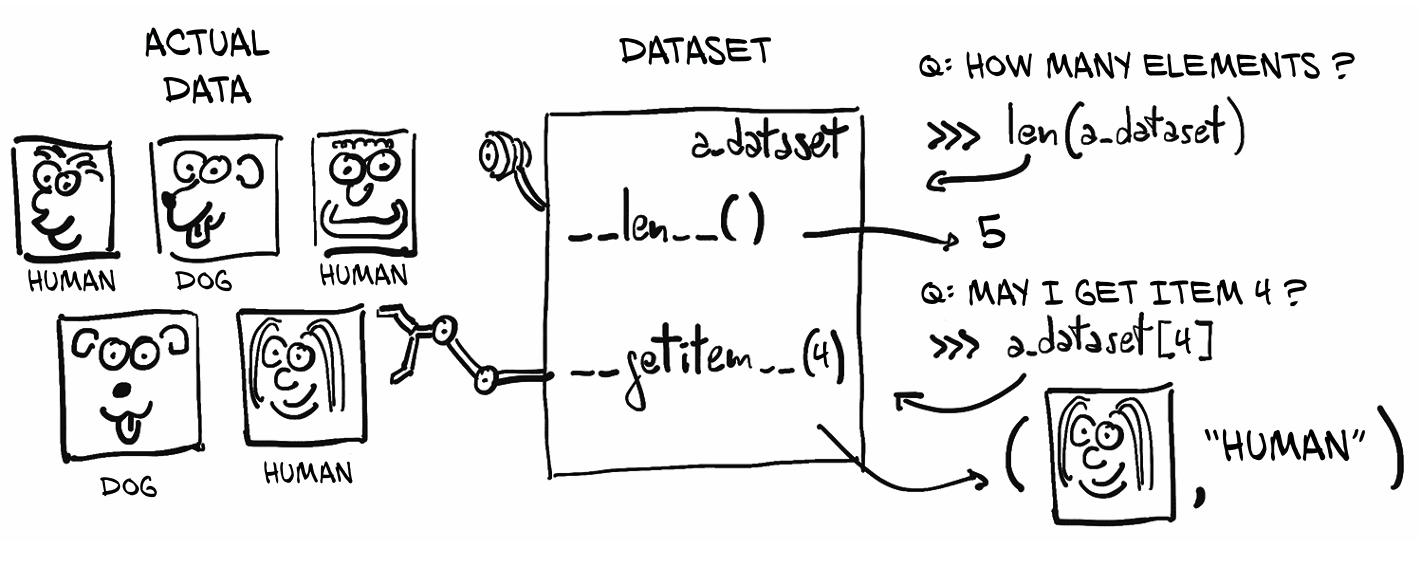
Python
print(len(cirfar10))
img, label = cifar10[0]
plt.imshow(img)
plt.show()数据集变换
在对图像进行操作前需要一种方法将PIL图像转换为 PyTorch 张量。这时需要使用torchvision.transforms模块,该模块定义了一组可组合的、类似函数的对象,这些对象可以作为参数传递给torchvision数据集,并在数据加载后尚未通过__getitem__返回之前对数据进行转换:
Python
from torchvision import transforms
dir(transforms)其中ToTensor变换可以将 NumPy 数组和 PIL 图像转换为张量,并将输出张量的维度布局设置为
Python
to_tensor = transforms.ToTensor()
img_t = to_tensor(img)
print(img_t.shape)之前选取的图像被转换为一个ToTensor作为参数传递给数据集.CIFAR10[1]
Python
tensor_cifar10 = datasets.CIFAR10(root=data_path, train=True, download=False,
transform=transforms.ToTensor())
img_t, _ = tensor_cifar10[0]
print(type(img_t))此时访问数据集中的某个元素返回的是一个张量而不是 PIL 图像,值得注意的是原始 PIL 图像中的值的范围是 0 到 255 (每通道8位),而ToTensor变换将数据转换为每通道32的浮点数,并将值缩放至 0.0 到 1.0 的区间:
Python
print(img_t.min(), img_t.max())Text
tensor(0.) tensor(1.)同时我们可以验证得到的图像是否相同:
Python
plt.imshow(img_t.permute(1, 2, 0))
plt.show()数据归一化
由于 CIFAR 数据集本身较小,我们可以将其堆叠在内存中直接进行处理:
Python
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10], dim=3)
print(imgs.view(3, -1).mean(dim=1))
print(imgs.view(3, -1).std(dim=1))view(3, -1)保留三个通道,并将所有剩余的维度合并为一个,自动计算出合适的大小。这里我们将
Text
tensor([0.4914, 0.4822, 0.4465])
tensor([0.2470, 0.2435, 0.2616])有了这些就可以初始化Normalize(归一化)变换,并将其与ToTensor变换后的结果拼接起来:
Python
transformed_cifar10 = datasets.CIFAR10(
root=data_path, train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2470, 0.2435, 0.2616))
]))此时从数据集中提取的图像绘制出来将不再是其实际图像:
Python
img_t, _ = transformed_cifar10[0]
plt.imshow(img_t.permute(1, 2, 0))
plt.show()归一化操作将RGB值移到了 0.0 到 1.0 的范围并改变了各通道的整体亮度。
区分鸟和飞机
构建数据集
第一步是将数据整理成合适的格式,我们可以创建一个仅包含鸟类和飞机的 Dataset 子类,由于数据集较小,我们可以直接过滤 CIRFAR-10 中的数据,并将标签重新映射为连续的序列:
Python
label_map = {0:0, 2:1}
class_names = ['airplane', 'bird']
cifar2 = [(img, label_map[label])
for img, label in cifar10
if label in [0,2]]
cifar2_val = [(img, label_map[label])
for img, label in cifar10_val
if label in [0,2]]一个全连接模型
我们可以将图像拉直成一个长的一维向量将其视为输入特征,即将nn.Linear层将特征数量缩减至合适的输出量。 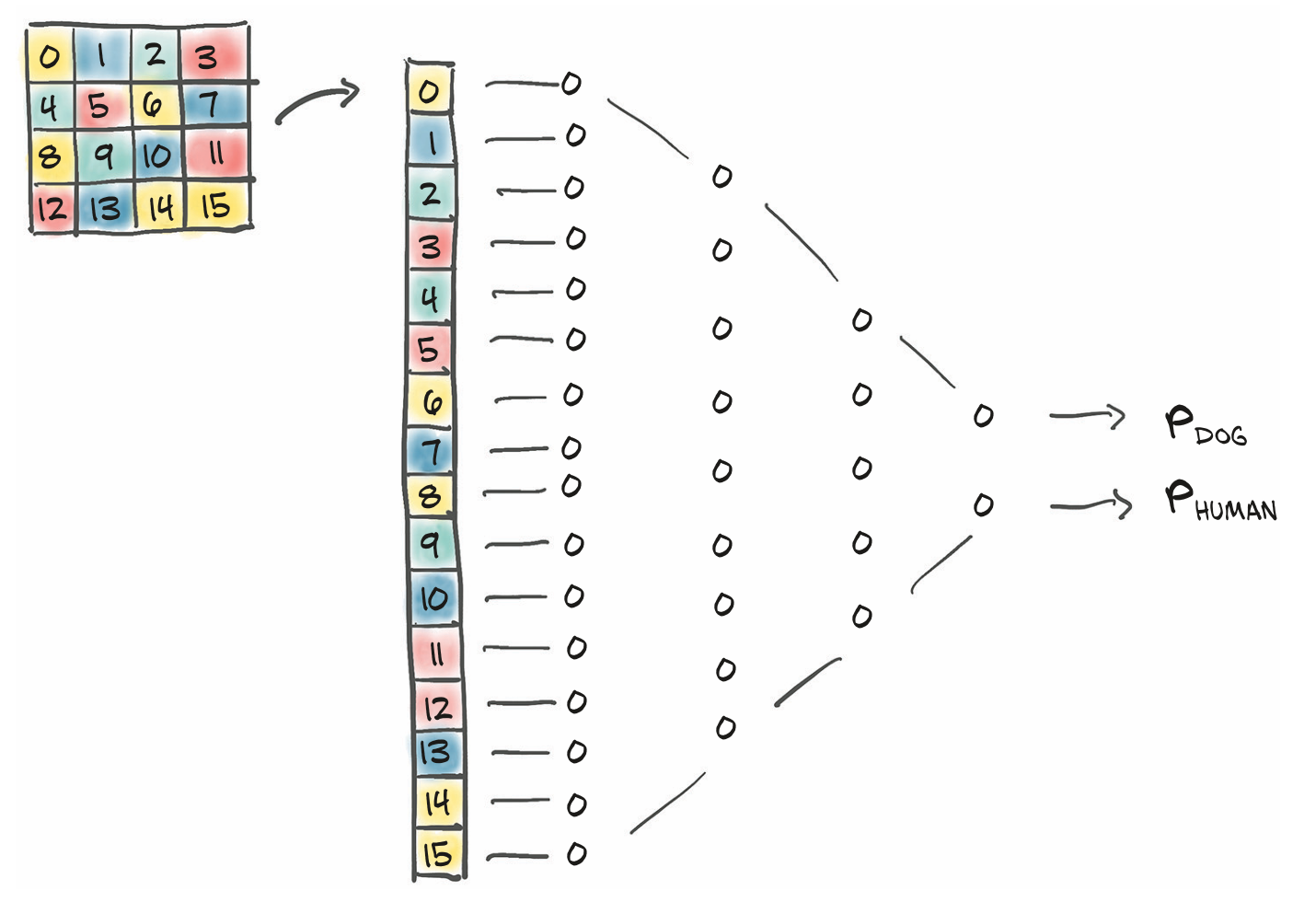
Python
import torch.nn as nn
n_out = 2
model = nn.Sequential(
nn.Linear(
3072, # 输入向量
512, #隐藏层大小
),
nn.Tanh(),
nn.Linear(
512,
n_out,
)
)我们任意地选择了 512 个隐藏特征,为了能够学习任意函数,神经网络至少需要一个隐藏层(即激活层)以及层间的非线性变换。
分类器的输出
在之前的学习中网络输出的是预测温度,在这里可以采用类似定义的方法:让网络输出一个单一的标量值(即n_out = 1),将标签转换为浮点数(飞机为 0.0,鸟为 1.0),并将这些值作为 MSELoss 的目标,这样九江分类问题转化为回归问题,但实际上处理的问题性质略有不同。 输出是分类性质的,当需要表示分类变量时应该采用该变量的独热编码表示,例如飞机用 [1,0],鸟用 [0,1]。由于分类器本身的限制,我们可以预期网络输出介于两者之间的值,即对于torch.tensor([0.0],[1.0]),第一个条目是“飞机”的概率,第二个是“鸟类”的概率,因此需要对输出进行一定的约束:
- 输出的每个元素必须在[0.0, 1.0]范围内
- 输出的所有元素之和必须为1.0 可以通过
softmax实现这一点(这在3B1B视频中也有详细介绍)
将输出表示为概率
Softmax的实现方式是对向量中每个元素计算指数,将每个元素初一所有元素指数的和:
Python
def softmax(x):
return torch.exp(x) / torch.exp(x).sum() Softmax 不具有尺度不变性。在
Softmax 不具有尺度不变性。在nn模块中可以直接调用softmax模块,而nn.Softmax要求我们指定应用 softmax 函数的维度:
Python
softmax = nn.Softmax(dim=1)
x = torch.tensor([[1.0, 2.0, 3.0],
[1.0, 2.0, 3.0]])
print(softmax(x))现在可以在模型末尾添加一个softmax层让神经网络输出概率:
Python
model = nn.Sequential(
nn.Linear(3072, 521),
nn.Tanh(),
nn.Linear(512, 2),
nn.Softmax(dim=1)
)我们可以在训练之前查看我们的图像:
Python
img, _ = cifar2[0]
plt.imshow(img.permute(1, 2, 0)) # 转换维度之前要确认之前导入的cifar2是由transformed_cifar10 导入的
plt.show()为了调用模型,我们需要输入具有正确的维度,即将
Python
image_batch = imgs.view(-1).unsqueeze(0)
out = model(image_batch)
print(out)得到的输出为
Text
tensor([[0.5732, 0.4268]], grad_fn=<SoftmaxBackward0>)这是经过初始模型得到的概率,其中grad_fn表示反向计算图的顶端,此时模型还不知道正确的输出应该是哪一个索引,我们可以通过argmax来获取输出的标签索引。当指定维度时,torch_max会返回该维度上的最大值以及该值出现的索引。 在这个实例中,我们需要沿着概率向量(而非跨批次)取最大值,因此维度为1:
Python
_, index = torch.max(out, 1)
print(index)接下来与之前相同,我们需要在训练过程中最小化损失函数。
分类的损失函数
在这里我们依然可以使用均方误差作为损失函数,但对于分类问题我们只需要惩罚错误的分类而不是让所有的输出都与[0.0, 1.0]或相反的值接近。因此我们只需要最大化正确类别对应的概率,即out[class_max],其中out是模型的输出,class_max是向量。对每个样本0代表“飞机”,1代表“鸟”。这个正确类别对应的概率被称为(在给定数据下)我们模型参数的似然,[2]我们希望损失函数在似然较低时非常高——低到其他类别的更高。反之,当似然高于其他类别时,损失函数应该较低。[3]这也解释了为什么做分类时,我们通常不用均方误差(MSE),而更倾向于使用交叉熵损失(Cross Entropy Loss)。 对于这类问题我们可以使用负对数似然(negative log likelihood, NLL)作为损失函数,其表达式为c_i是样本i的正确类别,如图所示: 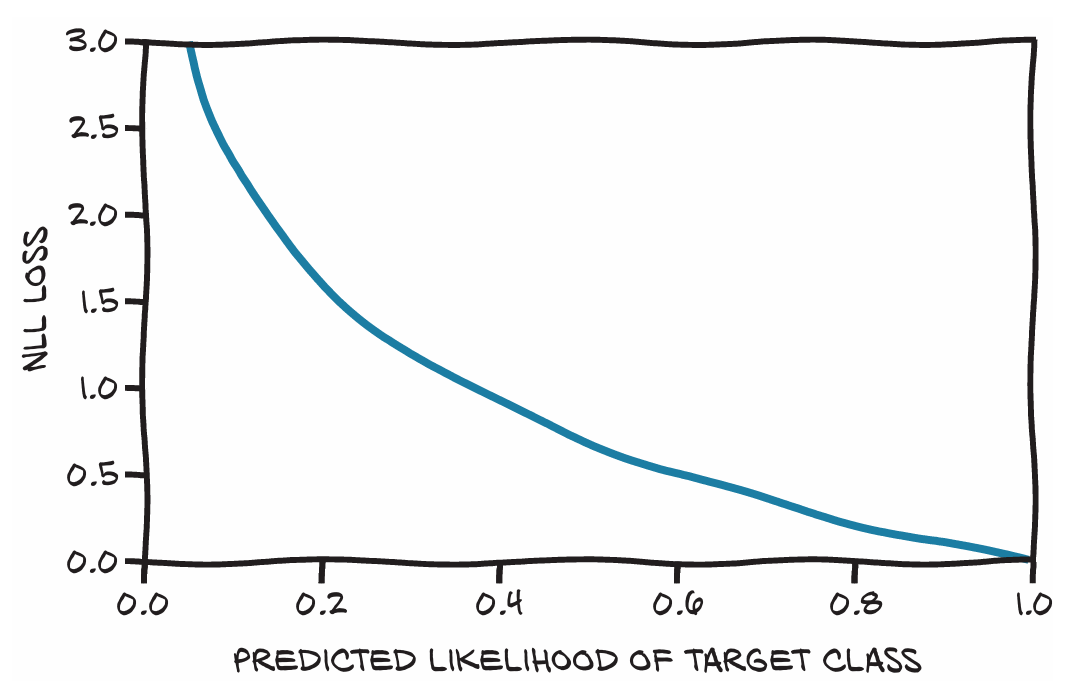
分类任务的损失可以通过如下方式计算,对于批次中每个样本:
- 执行前向传播,从最后一个(线性)层获取输出值
- 计算他们的 softmax 得到概率
- 去对应于正确类别的预测概率(参数的似然度)
- 计算其负对数并将其累加进损失函数中 PyTorch 中提供了
nn.NLLLoss类,但其并不接受概率作为输入,而是接受一个对数概率的张量作为输入,这是由于当概率接近于 0 时对于对数会较为棘手。因此我们需要使用nn.LogSoftmax替代nn.Softmax以确保计算在数值上的稳定,因此我们可以修改代码:
Python
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)
loss = nn.NLLLoss()
img , label = cifar2[0]
out = model(img.view(-1).unsqueeze(0))
print(loss(out, torch.tensor([label])))
训练分类器
与之前一样,我们可以训练分类器
Python
import torch.nn as nn
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
).to(device)
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
loss_fn = nn.NLLLoss()
n_epochs = 100
for epoch in range(n_epochs):
for img, label in cifar2:
img = img.to(device)
label = torch.tensor([label]).to(device)
out = model(img.view(-1).unsqueeze(0))
loss = loss_fn(out, torch.tensor([label]))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch: %d, Loss: %f" % (epoch, loss.item())) # 输出最后一张图像的损失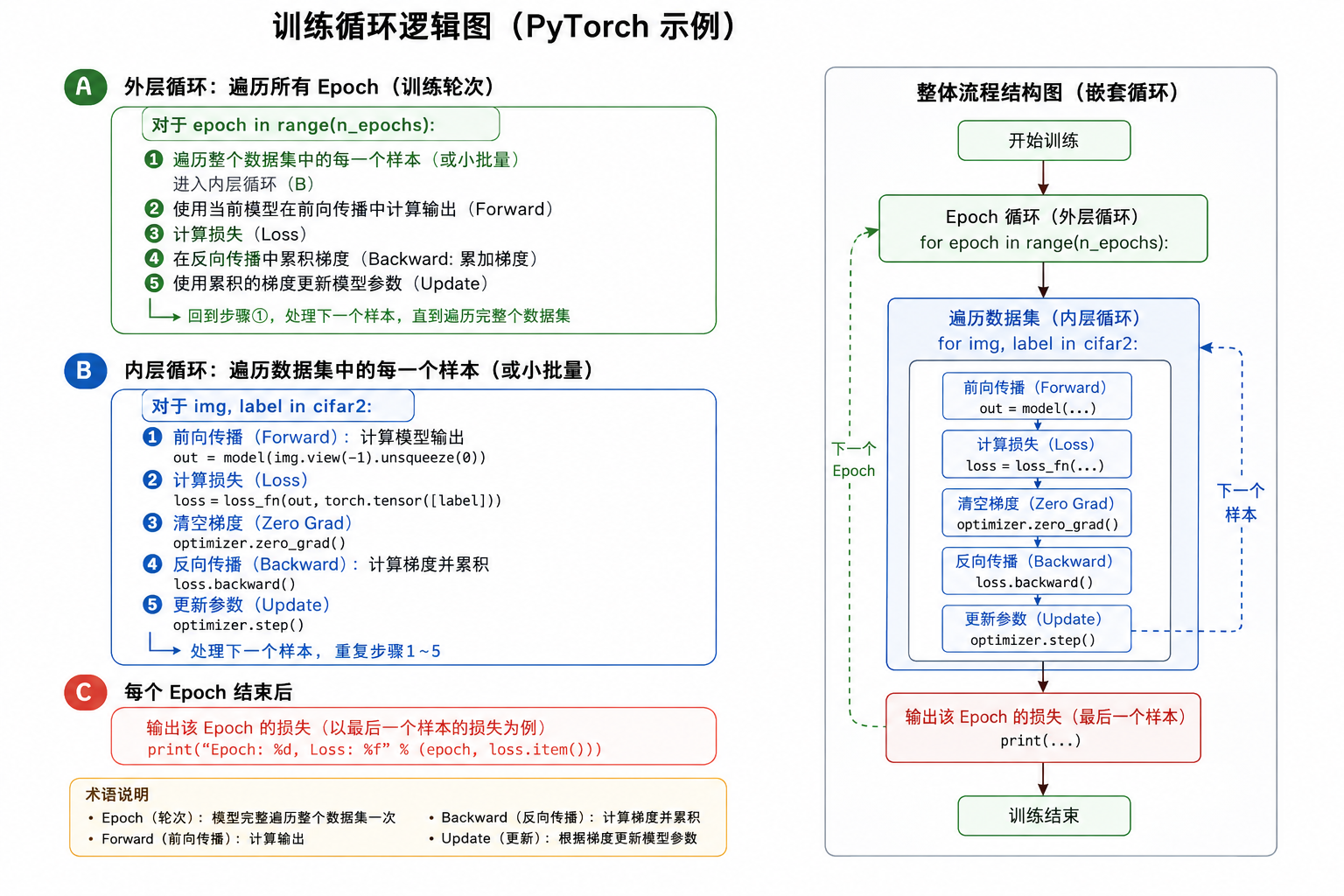
| 方式 | 怎么做 | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降 | 10,000 张全算完,求平均梯度,更新一次 | 梯度精确 | 太慢,显存放不下 |
| 随机梯度下降 | 每次只抽 1 张,算梯度,立刻更新 | 快 | 梯度波动巨大,训练不稳定 |
| 小批量梯度下降 | 每次抽 64 张(batch),算平均梯度,更新 | 两者折中,实际都在用 |
小批量(batch)通过随机梯度帮助跳出局部极小值,每个 epoch 洗牌确保每个 batch 的梯度近似全局梯度。batch size 和学习率一样是超参数(训练前人工设定),区别于网络的参数(训练中自动更新)。[4]
| 模型参数 | 超参数 | |
|---|---|---|
| 例子 | weight, bias | batch_size, learning_rate |
| 谁决定 | 训练中自动更新 | 在训练前设定 |
| 变化 | 每步都在变 | 一次设定,训练全程不变 |
此时Batch Size = 1,每个 Epoch 里,每看一张图片就更新一次参数。torch.utils.data模块中有一个名为DataLoader的类有助于对小批量数据进行打乱和组织:
Python
import torch.nn as nn
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64, shuffle=True)
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
).to(device)
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
loss_fn = nn.NLLLoss()
n_epochs = 100
for epoch in range(n_epochs):
for imgs, labels in train_loader:
batch_size = imgs.shape[0]
outputs = model(imgs.view(batch_size, -1).to(device))
loss = loss_fn(outputs, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch: %d, Loss: %f" % (epoch, loss.item())) # 打印随机批次损失在每个内部迭代中,imgs时应该大小为labes是一个大小为 64 的张量,包含各标签的索引。通过训练可以看到损失有所下降,因此我们可以计算模型在验证集上的准确率:
Python
transformed_cifar10_val = datasets.CIFAR10(
root=data_path, train=False, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2470, 0.2435, 0.2616))
]))
cifar2_val = [(img, label_map[label])
for img, label in transformed_cifar10_val
if label in [0,2]]
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64, shuffle=False)
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in val_loader:
batch_size = imgs.shape[0]
outputs = model(imgs.view(batch_size, -1).to(device))
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy of the model on the 10000 test images: %d %%" % (correct/total*100))最终得到模型的准确率:Accuracy of the model on the 10000 test images: 81 %。 虽然不算很完美但已经取得了阶段性的成功,我们还可以为模型增加更多曾来提升模型的深度和容量:
Python
model = nn.Sequential(
nn.Linear(3072, 1024),
nn.Tanh(),
nn.Linear(1024, 512),
nn.Tanh(),
nn.Linear(512, 128),
nn.Tanh(),
nn.Linear(128, 2),
nn.LogSoftmax(dim=1)
).to(device)我们希望让特征数量向输出层过渡时平滑地减少,希望中间层能更好地将信息压缩到越来越短的中间输出层中nn.LogSoftmax与nn.NLLLoss的组合等同于使用nn.CrossEntropyLoss。这正是 PyTorch 的特殊之处,nn.NLLLoss实际上时计算交叉熵,输入的时 log 概率预测值,而nn.CrossEntropyLoss则采用评分。反正就是将最后的nn.LogSoftmax层去掉直接使用nn.CrossEntropyLoss:
Python
model = nn.Sequential(
nn.Linear(3072, 1024),
nn.Tanh(),
nn.Linear(1024, 512),
nn.Tanh(),
nn.Linear(512, 128),
nn.Tanh(),
nn.Linear(128, 2),
).to(device)
loss_fn = nn.CrossEntropyLoss()此时得到的数值与使用nn.LogSoftmax与nn.NLLLoss的完全一致,但模型输出的将无法直接解释为概率,而需要将其通过softmax才能得到概率值。 模型在训练集的准确率只有80%左右,更大的模型确实可以带来准确率的提升,但相较于训练集的准确率差距很大,表明模型存在过拟合。PyTorch 提供的parameters()方法可以快速统计模型参数数量。
Python
numel_list = [p.numel()
for p in model.parameters()
if p.requires_grad == True]
print(sum(numel_list), numel_list)Text
3737474 [3145728, 1024, 524288, 512, 65536, 128, 256, 2]与初始模型对比扩大了很多倍,而神经网络在像素数量增加时会难以扩展。
全连接的局限性
在使用全连接时使得图像中任意像素与其他像素相关;另一方面对相邻或距离相近像素的信息没有得到很好的应用,即全连接具有平移不变性,因此我们需要对数据集进行增强,即在训练过程中对图像施加随机平移一边网络中有机会看到图像中各个位置的飞机。解决这一问题的方法是使用卷积层来改变当前的模型。 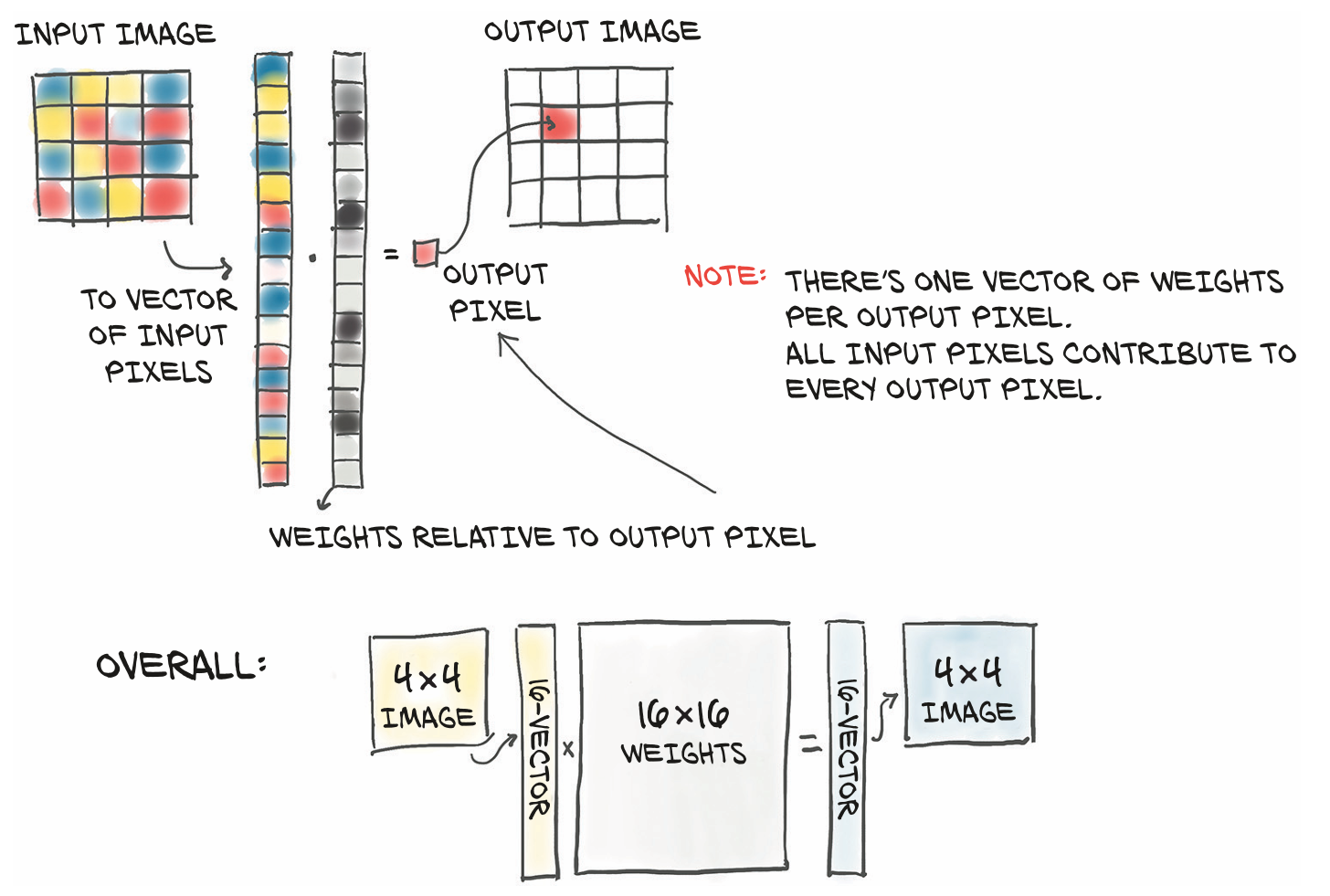
在 Python 和 PyTorch 中,下划线
_被称为占位符(Placeholder)。它的核心作用是:占个位置,用来接收那些你“不得不读取,但后续根本用不上”的数据。 ↩︎假设输入的样本是一只鸟(真实标签
label = 1)。 模型经过 Softmax 后的输出概率为:out = [0.3, 0.7],此时,正确类别(鸟)对应的模型预测概率就是out[1] = 0.7。这个0.7就是似然(Likelihood)——即在当前模型参数下,模型认为这个样本是“鸟”的概率有多大。 ↩︎当似然很低时(比如样本是鸟,模型给鸟的概率
out[1]只有0.01):说明模型错得很离谱,此时损失函数必须暴涨(非常高),给模型一个巨大的惩罚,迫使它进行大幅度参数调整。当似然很高时(比如样本是鸟,模型给鸟的概率out[1]达到了0.99):说明模型预测得非常准,此时损失函数应该接近于 0(非常低),不打扰模型的当前状态。 ↩︎如果每轮都按数据集原始顺序喂数据(图 1→图 2→...→ 10000),网络会"记住顺序"而非"学习特征"。打乱顺序后,每个 batch 的梯度带着随机波动,反而帮助网络探索更广的 loss 地形。64 张图的平均梯度 ≠ 10,000 张图的平均梯度。但它已经大致指向正确的下降方向——而且 64 张算一次比 10,000 张算一次快 150倍。精确的(全量)梯度可能把网络引导到一个看起来最低但其实不够好"的坑里(局部极小值)。而小批量带来的梯度噪声像一阵随机风——有时能把网络推出浅坑让它有机会掉进更深的(更好的)坑。假设你的数据是 猫猫猫猫...狗狗狗狗飞机飞机——不洗牌的话,一个 batch 可能全是猫,这 batch 的梯度只教你认猫,对狗和飞机毫无意义。洗牌后每个 batch 都是各类混合,梯度才"代表全局"。 ↩︎