Appearance
使用神经网络拟合数据
人工神经元
更多的激活函数
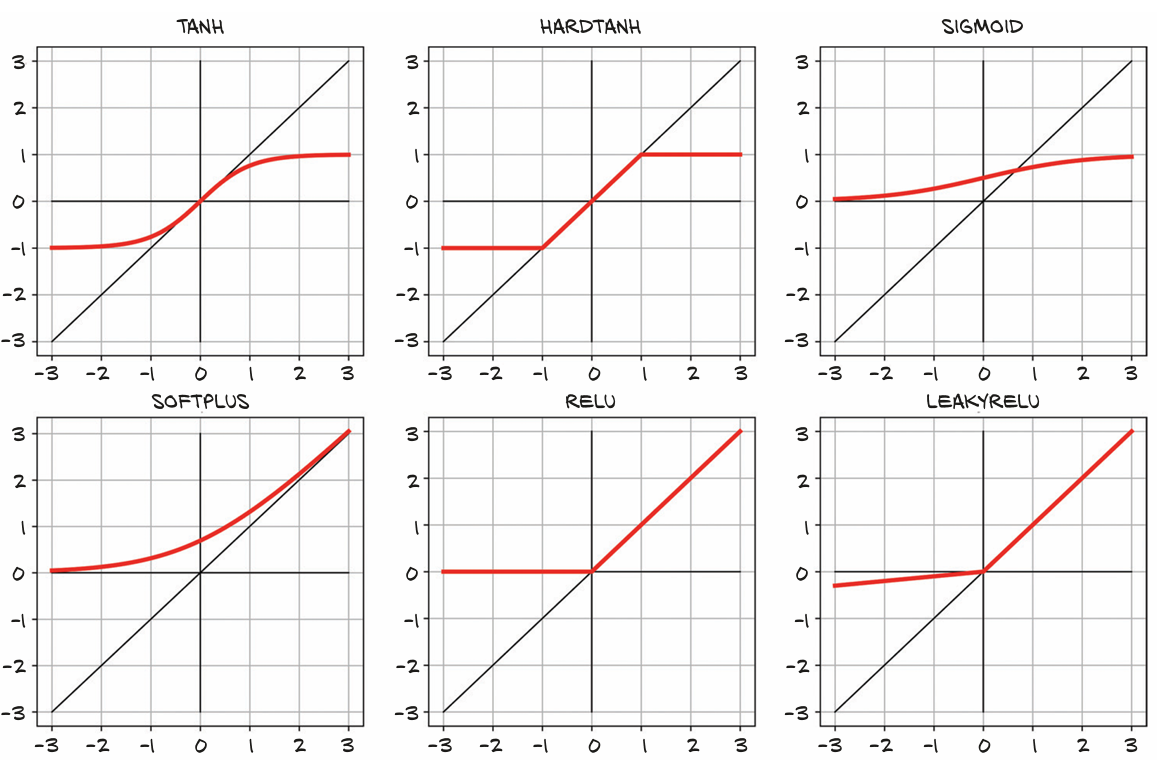
激活函数的特征:
- 非线性:若没有激活函数,重复计算
只会得到相同形式的函数,而非让整个网络能够逼近更复杂的函数 - 可微分:使得梯度能够反向传播(不连续点也是可接受的) 共性:
- 至少存在一个敏感区间,在该区间内输入的显著变化会导致输出发生显著变化
- 许多函数存在不敏感(或饱和)区间,此区间内输入的变化几乎不会引起输出的变化,Hardthan函数可以通过构造分段线性函数逼近 此外激活函数通常会在输入与输出接近正负无穷时到达上界/下界
PyTorch nn 模块
torch.nn是 PyTorch 专门处理神经网络的子模块,可以将一个或多个Parameter实例作为其属性,这些参数本质是张量,其数值在训练过程中会被优化。此外模块可以包含一个或多个子模块(即nn.Module的子类)作为属性,并能够自动追踪这些子模块的参数。
数据准备
Python
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
# edgeitems – 每个维度总结中数组项的开头和结尾的项数
# linewidth – 用于插入换行的每行字符数
torch.set_printoptions(edgeitems=2, linewidth=75)
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
print(len(t_u))
t_c = torch.tensor(t_c).unsqueeze(1) # torch.tensor() 把列表转换成张量
t_u = torch.tensor(t_u).unsqueeze(1) # unsqueeze返回一个新的张量,在其指定的索引位置插入一个大小为 1 的维度。
print(t_u.shape)
n_samples = t_u.shape[0] # 获取总样本数
n_val = int(0.2 * n_samples) # 计算测试集所占样本量
shuffled_indices = torch.randperm(n_samples) # 生成随机打乱索引
# 切分训练集与测试集索引
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
print(train_indices, val_indices)
# 选出测试集与训练集
t_u_train = t_u[train_indices]
t_c_train = t_c[train_indices]
t_u_val = t_u[val_indices]
t_c_val = t_c[val_indices]
t_un_train = 0.1 * t_u_train
t_un_val = 0.1 * t_u_val使用__call__而不是forward
PyTorch 提供的所有 nn.Module子类都定义了__cal__方法,这使得我们可以实例化一个nn.Linear模块,并像调用函数一样调用他:
Python
linear_model = nn.Linear(1, 1)
print(linear_model(t_un_val))在调用nn.Module实例时实际上是调用一个名为forward的方法并传入相同的参数进行前向传播,而__call__方法在调用forward前后还会执行一些其他操作,以下是省略 JIT 相关部分的Module.__call__方法的实现:
Python
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
hook(self, input)
result = self.forward(*input, **kwargs)
for hook in self._forward_post_hooks.values():
hook_result = hook(self, input, result)
# ...
for hook in self._backward_hooks.values():
# ...
return resultnn.Linear线性回归模型
对于nn.Linear其包含三个参数:输入特征的数量、输出特征的数量以及线性模型是否包含偏置项(默认为True),对于只有一个输入与输出的线性模型,其输入与特征均为 1 ,只需要一个权重linear_model.weight与一个偏置inear_model.bias:
批量输入
假设我们需要对10个样本进行nn.Linear,我们可以创建一个大小为
Python
x = torch.ones(10,1)
linear_model(x)以批量图像处理为例,输入一个大小为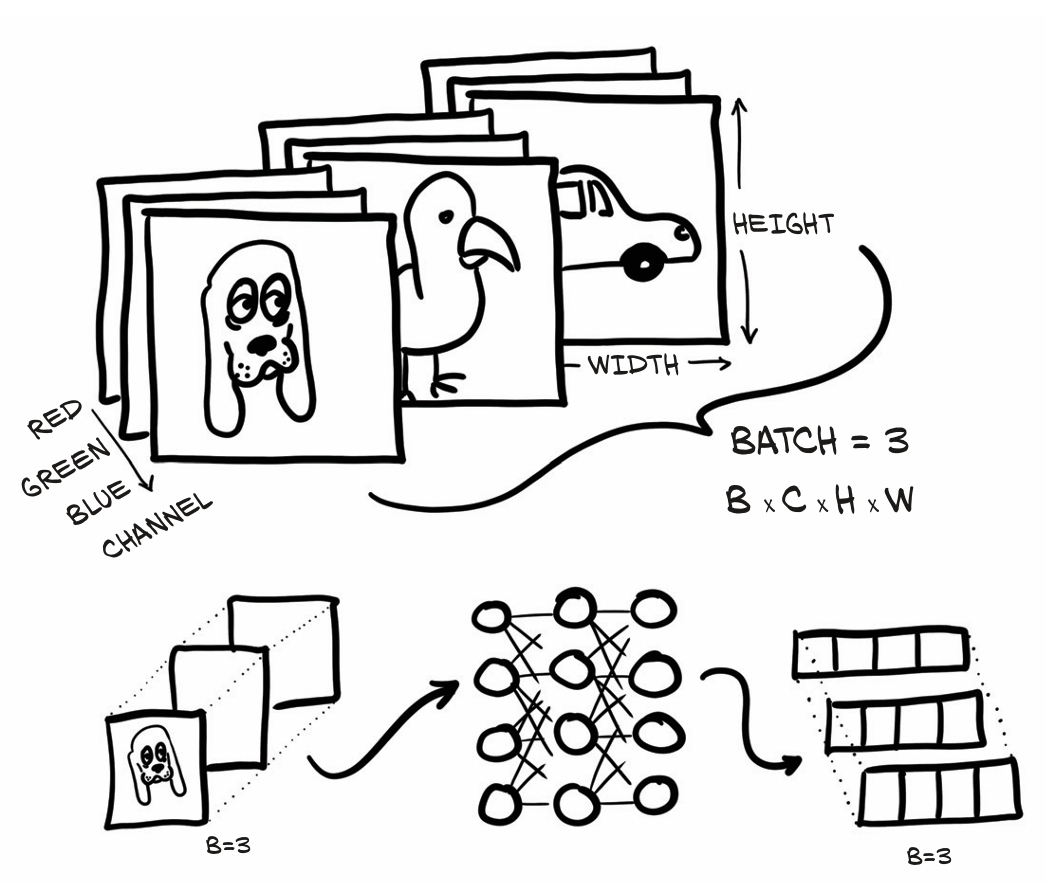
优化批处理
在之前的处理中我们需要自行创建参数并将其传入opt.SGD,现在可以直接使用parameters方法向任何nn.Module查询其自身或子模块拥有的参数列表,该调用会递归调用模块init构造函数中定义的子模块并返回遇到的参数的扁平列表,我们可以将其传递给优化器的构造函数optimizer:
Python
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)
print(linear_model.parameters())
print(list(linear_model.parameters()))输出:
Text
<generator object Module.parameters at 0x000001D95FA654E0>
[Parameter containing:
tensor([[-0.5721]], requires_grad=True), Parameter containing:
tensor([-0.5433], requires_grad=True)]因为优化器需要通过梯度下降进行批量优化,当调用training_loss_backward()时,梯度会累计在计算图的叶节点上,此时当调用optimizer.step()时,它会遍历每个参数并根据其grad属性中存储的值按比例调整参数:
Python
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val, t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train) # 现在传入的是模型而不是单个参数 即将所有内部参数封装进model中
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val) # 此处同上
loss_val = loss_fn(t_p_val, t_c_val)
optimizer.zero_grad()
loss_train.backward() # 传入损失函数
optimizer.step()
if epoch == 1 or epoch % 1000 == 0:
print(f"Epoch: {epoch}, Training loss: {loss_train.item():.4f}, Validation loss: {loss_val.item():.4f}")接下来我们只需要调用training_loop并利用其中的损失函数nn.MSELoss(即均方误差,这与使用张量处理真实数据中定义的loss_fn完全一致):
Python
training_loop(
n_epochs = 3000,
optimizer = optimizer,
model = linear_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val
)
print(linear_model.weight)
print(linear_model.bias)得到输出:
Text
Epoch: 1, Training loss: 212.4924, Validation loss: 181.3738
Epoch: 1000, Training loss: 3.4577, Validation loss: 2.7266
Epoch: 2000, Training loss: 2.9852, Validation loss: 2.7311
Epoch: 3000, Training loss: 2.9778, Validation loss: 2.7318
Parameter containing:
tensor([[5.3758]], requires_grad=True)
Parameter containing:
tensor([-17.2740], requires_grad=True)这与我们在之前得到的结果一致
线性模型到神经网络
在保持原有设置不变的情况下重新定义模型即可构造一个最简单的神经网络:一个线性模块,接一个激活函数,连接另一个线性模块如图: 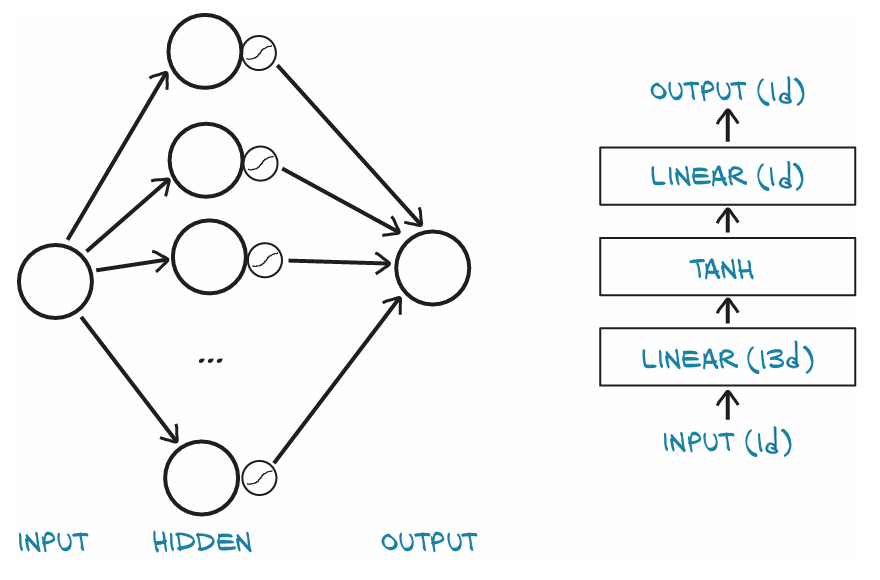
nn通过nn.Sequential容器提供了一种简单的模块串联方式:
Python
seq_model = nn.Sequential(
nn.Linear(1, 13),
nn.Tanh(),
nn.Linear(13, 1))
print(seq_model)最终生成的模型会接收作为nn.Seqential参数制定到第一个模块所期望的输入,将中间输出传递给后续模块并生成由最后一个模块返回的输出——该模型从1个输入特征扩展为13个隐藏特征,通过
检查参数
调用model.parameters()将从第一个和第二个线性模块中收集权重和偏置:
Python
[param.shape for param in seq_model.parameters()]Text
[torch.Size([13, 1]), torch.Size([13]), torch.Size([1, 13]), torch.Size([1])]这些是优化器获取到的张量。在调用optimizer.backward()后这些参数都会被填充对应的梯度,随后优化器调用optimize.step()时会根据这些梯度更新参数值。关于nn.Modules的参数,在检查由多个子模块组成的模型参数时,能够按名称识别参数会非常方便,对此有一个专门的方法named_paramters:
Python
for name, param in seq_model.named_parameters():
print(name, param.size())Text
0.weight torch.Size([13, 1])
0.bias torch.Size([13])
2.weight torch.Size([1, 13])
2.bias torch.Size([1])在Sequential中,每个模块的名称就是他在参数中出现的序号。此外,Sequential还支持OrderedDict,通过它我们可以给传递给Sequential的每个模块命名:
Python
seq_model = nn.Sequential(OrderedDict([
('hidden_linear', nn.Linear(1, 8)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(8, 1))
]))
print(seq_model)Text
Sequential(
(hidden_linear): Linear(in_features=1, out_features=8, bias=True)
(hidden_activation): Tanh()
(output_linear): Linear(in_features=8, out_features=1, bias=True)
)这使得我们可以为子模块赋予更具说明性的名称: 再次调用parameters()可以得到:
Text
hidden_linear.weight torch.Size([8, 1])
hidden_linear.bias torch.Size([8])
output_linear.weight torch.Size([1, 8])
output_linear.bias torch.Size([1])这样得到的结果更具有描述性,我们还可以通过将子模块作用属性来访问特定参数:
Python
print(seq_model.output_linear.bias)这对于检查参数或其梯度非常有用,例如在训练过程中监控梯度:
Python
optimizer = optim.SGD(seq_model.parameters(), lr=1e-3)
training_loop(
n_epochs = 5000,
optimizer = optimizer,
model = seq_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val
)
print('output', seq_model(t_un_train))
print('answer', t_c_val)
print('hidden', seq_model.hidden_linear.weight.grad)Text
tensor([0.0467], requires_grad=True)
Epoch: 1, Training loss: 144.4501, Validation loss: 443.5661
Epoch: 1000, Training loss: 4.6016, Validation loss: 43.7563
Epoch: 2000, Training loss: 3.3176, Validation loss: 24.3978
Epoch: 3000, Training loss: 2.7587, Validation loss: 15.2598
Epoch: 4000, Training loss: 2.5157, Validation loss: 10.3273
Epoch: 5000, Training loss: 2.3920, Validation loss: 7.5144
output tensor([[-3.3608],
[19.7097],
[15.1072],
[12.1273],
[ 0.7087],
[12.3949],
[ 1.3543],
[ 7.3395],
[13.6634]], grad_fn=<AddmmBackward0>)
answer tensor([[ 8.],
[28.]])
hidden tensor([[ 0.0161],
[ 0.0094],
[ 0.0157],
[-0.0081],
[-0.3196],
[ 0.2783],
[-0.3033],
[ 0.2375]])和线性模型对比
我们可以对所有数据进行模型病故,并观察其与直线的差异:
Python
from matplotlib import pyplot as plt
t_range = torch.arange(20., 90.).unsqueeze(1)
fig = plt.figure(dpi=600)
plt.xlabel('Fahrenheit')
plt.ylabel('Celsius')
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.plot(t_range.numpy(), seq_model(0.1 * t_range).detach().numpy(), 'c-')
plt.plot(t_u.numpy(),seq_model(0.1 * t_u).detach().numpy(), 'kx')
plt.show()结果如图所示,可以发现神经网络存在过拟合倾向: 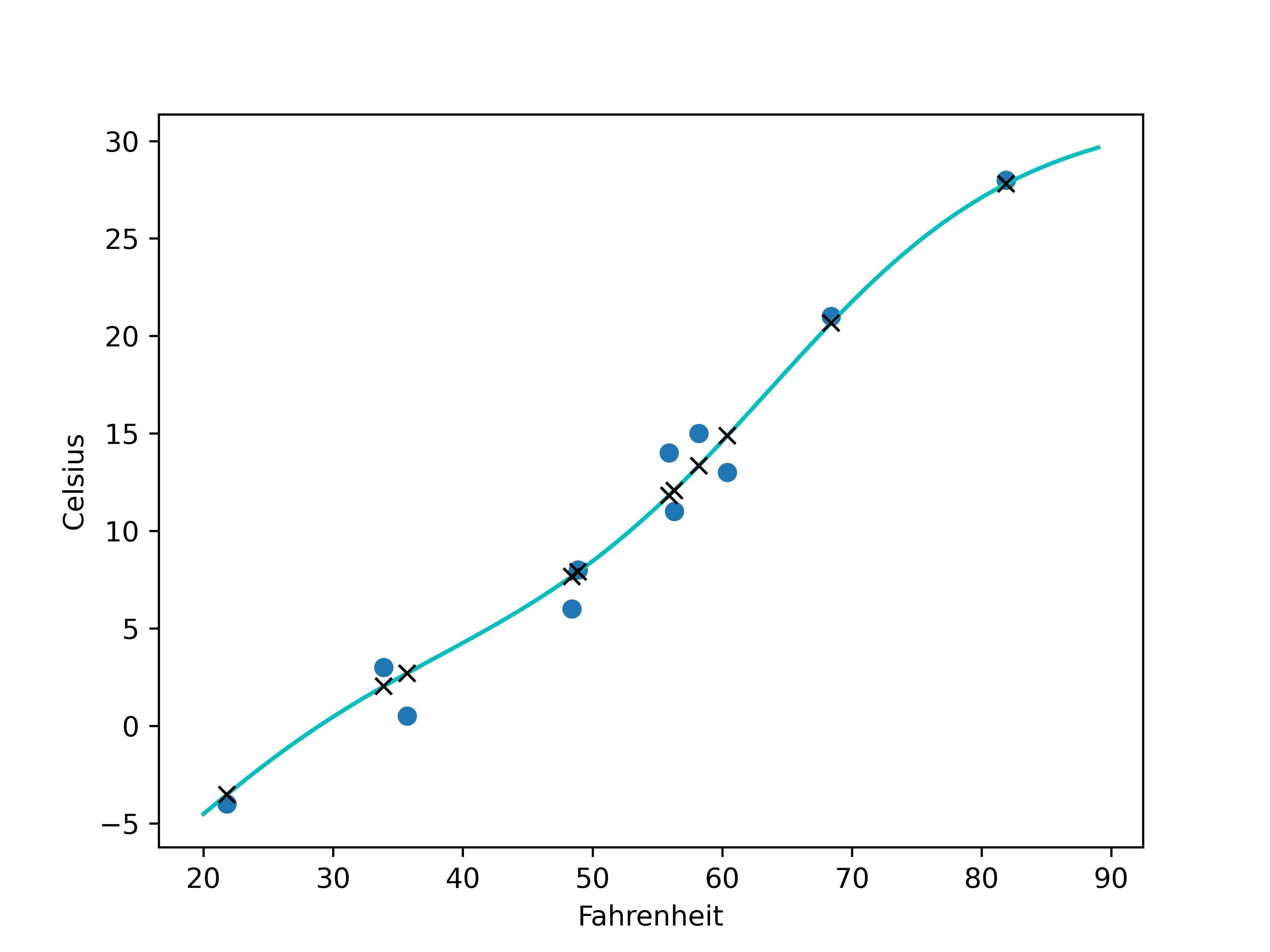 其中输入数据为圆圈,模型输出为X号
其中输入数据为圆圈,模型输出为X号